Multithreading Gameplay Logic (Part2)
/So today I'll be going over my second approach to multithreading gameplay logic. This approach is similar to the actor model , in that entities are capable of updating their internal state, but to update other entities, they must send messages. An extension that many engines add to the actor model is a dependency system. The dependency system helps with task batching in the multithreading phase, and determines which messages can be sent immediately or deferred until the end of the frame.
In my approach, there are five important classes. EBusTraits, EBus, CEntityBusPeer, CActor, CActorComponent. The EBusTrait's responsibility is to provide custom configurations on a per bus basis. EBus is the specific bus and handles dispatch logic for a message. Entity Bus Peers are equivalent to the actors in the actor model, in that they send and receive messages while CActor and CActorComponents are similar to Actors and Actor Components in Unreal Engine 4, and are derived from CEntityBusPeer.
As previously stated, I have incorporated a dependency system to this approach. Actors/ActorComponents that are likely to access each other during a tick add themselves to a dependency list. In the beginning of the frame, All Actors and Components that are dependent on each other are put into a single job and sent to update on the same thread. This batching approach is used in (1) and (2).

Definition of the transform bus traits. Messages sent on this bus must be dispatched during the "Asynchronous" phase. (as in they must be executed at the end of the frame)

Definitions of specific bus'.
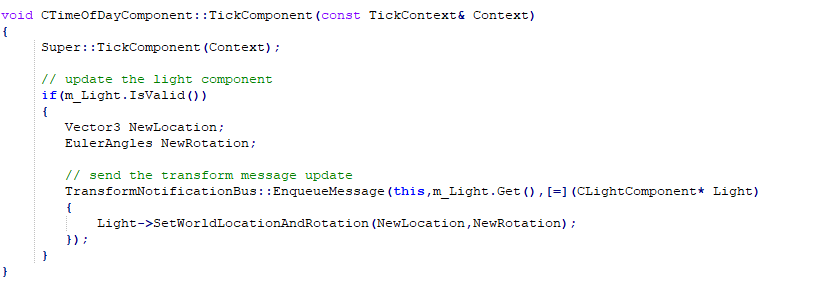
Example of sending a message to update a light component on the transform notification bus.
As one can see , I chose to take a different approach when it came to the messaging system. Many messaging systems choose to rely on either an uber-message or a derived message class approach. Seeing as there might be hundreds , or thousands, of messages, I chose to use lambdas.
PROS
1) Actors/Components are completely decoupled , allowing for far more efficient multithreading than the previous approach.
2) Easier to transfer old code bases to this approach by creating a dependency or converting any Actor/Component manipulation to an asynchronous message.
3) Allows parent entities / components to be updated prior to children.
CONS
1) Requires some external systems to become aware of the new multithreaded architecture. For example, any thread can be processing a task that can be reading or writing from the physics world. To compensate for this, some approaches choose to buffer any physics changes until a certain point, meaning that all ray casts will be running against an old state.
2) Because Actors/Components are updated one at a time, it becomes impossible to leverage any optimizations that could be done through a batching approach.